
Avoir la capacité de mener des opérations de forensic à grande échelle est souvent un problème. En effet la méthode traditionnelle consiste à charger une image disque dans un outil tel que The Sleuth Kit ou Plaso et utiliser l’interface de l’outil pour lire un seul prélèvement. C’est bien mais comment faire pour 50 machines ? Pour 200 ? Ou même pour en traiter 10 si vous êtes tout seul ?
De la même manière qu’un SOC doit faire rentrer tous les logs dans son SIEM, en tant qu’opérateurs forensic il faut centraliser toutes les données dans un outil qui va nous permettre de mener nos recherches, créer nos dashboards, etc…
Ainsi, l’outil Dissect va nous permettre de répondre au problème de l’extraction des données depuis des prélèvements forensic. C’est un très bon framework qui nous permet d’extraire des artefacts système pour Windows, Linux et Mac à partir de prélèvements variés. Très simplement, il nous permet de prendre ce que Dissect nomme des conteneurs (un format de donnée varié) et d’en extraire les artefacts que l’on souhaite lire, par exemple les evtx. Cela présente un avantage de performance important : on peut choisir un seul artefact contrairement à des outils comme Plaso qui traitent l’ensemble des artefacts à leur disposition.
Dissect setup
Pour installer Dissect on va se reposer sur pipx, qui nous permet d’installer des outils basés sur Python et de les isoler dans des environnements virtuels.
sudo apt update
sudo apt install -y pipx
pipx ensurepath
source ~/.bashrc
Puis :
pipx install dissect
Parsing des données
Pour extraire des données d’un artefact avec Dissect, on va utiliser la commande target-query. Dissect va se charger de reconnaître le format du disque (raw, ova, qcow, etc…) et extraire les données en fonction de la fonction utilisée. Ci-dessous on extrait les evtx :
target-query E01-DC01/20200918_0347_CDrive.E01 -f evtx
Cette commande peut ensuite se combiner avec rdump qui permet de lire et d’écrire les enregistrements Dissect de différentes manières. On pourrait par exemple écrire les enregistrements en JSON, les envoyer à Splunk ou même Elasticsearch.
Déploiement d’ELK
Pour mettre en place ELK on va utiliser un projet qui utilise Docker pour gérer l’installation de la stack. Cela nous permet d’avoir Elasticsearch, Kibana et Logstash déployables très facilement. Voici la procédure à suivre :
git clone https://github.com/deviantony/docker-elk
On édite le fichier setup/roles/logstash_writer.json pour étendre les droits de Logstash à tous les index :
...
"indices": [
{
"names": [
"*"
],
...
Avant de démarrer la stack, assurez-vous d’avoir modifié les mots de passe par défaut dans le fichier .env à la racine du projet. Modifiez tous les mots de passe changeme par de vrais mots de passe : openssl rand -base64 32.
Puis on peut démarrer la stack (bien faire les commandes dans cet ordre pour que la configuration soit correcte) :
docker compose up kibana-genkeys
docker compose up setup
docker compose up -d
Configurer ELK
On va commencer par ajouter un template pour nos index Dissect. Ce template va nous permettre d’étendre le nombre de champs qu’on pourra mettre dans nos évènements parsés par Dissect car la limite par défaut est de 1000 et cela se dépasse sur de nombreux évènements. Il nous permet également de spécifier les champs de type date avec les mappings. On peut écrire le fichier suivant :
{
"index_patterns": ["dissect-*"],
"template": {
"settings": {
"index.mapping.total_fields.limit": 3000,
"index.mapping.total_fields.ignore_dynamic_beyond_limit": true
},
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"ts": { "type": "date" }
}
}
},
"priority": 200
}
Puis on peut le poster sur l’API Elasticsearch :
source .env
curl -u elastic:${ELASTIC_PASSWORD} \
-H "Content-Type: application/json" \
-X PUT http://localhost:9200/_index_template/dissect-template \
--data-binary @template-dissect.json
On peut maintenant configurer la pipeline Logstash. Celle-ci va exposer le port 50000 pour y lire les évènements qu’on va indexer. Ajoutez un fichier, par exemple logstash/pipeline/dissect.conf :
input {
tcp {
port => 50000
mode => "server"
codec => json_lines
ecs_compatibility => "v8"
dns_reverse_lookup_enabled => false
}
}
filter {
mutate {
remove_field => [ "_version" ]
}
if [ts] {
date {
match => [ "ts", "ISO8601" ]
target => "@timestamp"
}
}
if [_classification] {
mutate {
copy => { "_classification" => "[event][dataset]" }
}
} else {
mutate {
add_field => { "[event][dataset]" => "dissect.data" }
}
}
if [_source] {
mutate {
copy => { "_source" => "[event][module]" }
}
} else {
mutate {
add_field => { "[event][module]" => "dissect" }
}
}
mutate {
add_field => { "ingest_source" => "tcp" }
remove_field => [ "_source", "_classification" ]
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
user => "logstash_internal"
password => "${LOGSTASH_INTERNAL_PASSWORD}"
index => "dissect-%{[event][dataset]}-%{+YYYY.MM.dd}"
}
}
On doit également supprimer le fichier de config par défaut :
rm logstash/pipeline/logstash.conf
Indexation
Avec la commande suivante on va :
- extraire les evtx de l’image disque
- les parser et les formatter correctement en JSON en ajoutant quelques champs informatifs
- les envoyer au port 50000 qu’on a ouvert précédemment
target-query file.E01 -f evtx -q \
| rdump \
-J \
--record-classification evtx \
-X _version \
| nc -N logstash 50000
Et voilà ! On n’a plus qu’à patienter pendant que les données s’indexent.
À tout moment vous pouvez suivre le processus d’indexation à la recherche d’erreurs avec
docker logs docker-elk-logstash-1 -f
Premières recherches
Rendez-vous dans Kibana sur http://votreip:5601. Si vous n’avez pas changé les identifiants dans le .env, ils sont par défaut elastic:changeme. Rendez-vous ensuite dans Analytics > Discover, c’est ici qu’on va retrouver notre interface de recherche.
Cliquez ensuite sur Try ES|QL pour bénéficier de ce nouveau langage, proche des fonctionnalités du SPL de Splunk et très puissant ! Vous pouvez commencer à écrire vos recherches ainsi :
FROM dissect-dissect.data-*
| WHERE EventID == 4624
| STATS hosts = VALUES(hostname), providers = VALUES(Provider_Name),
subjects = VALUES(SubjectUserName), targets = VALUES(TargetUserName),
count = COUNT(*)
BY LogonType
| SORT count DESC
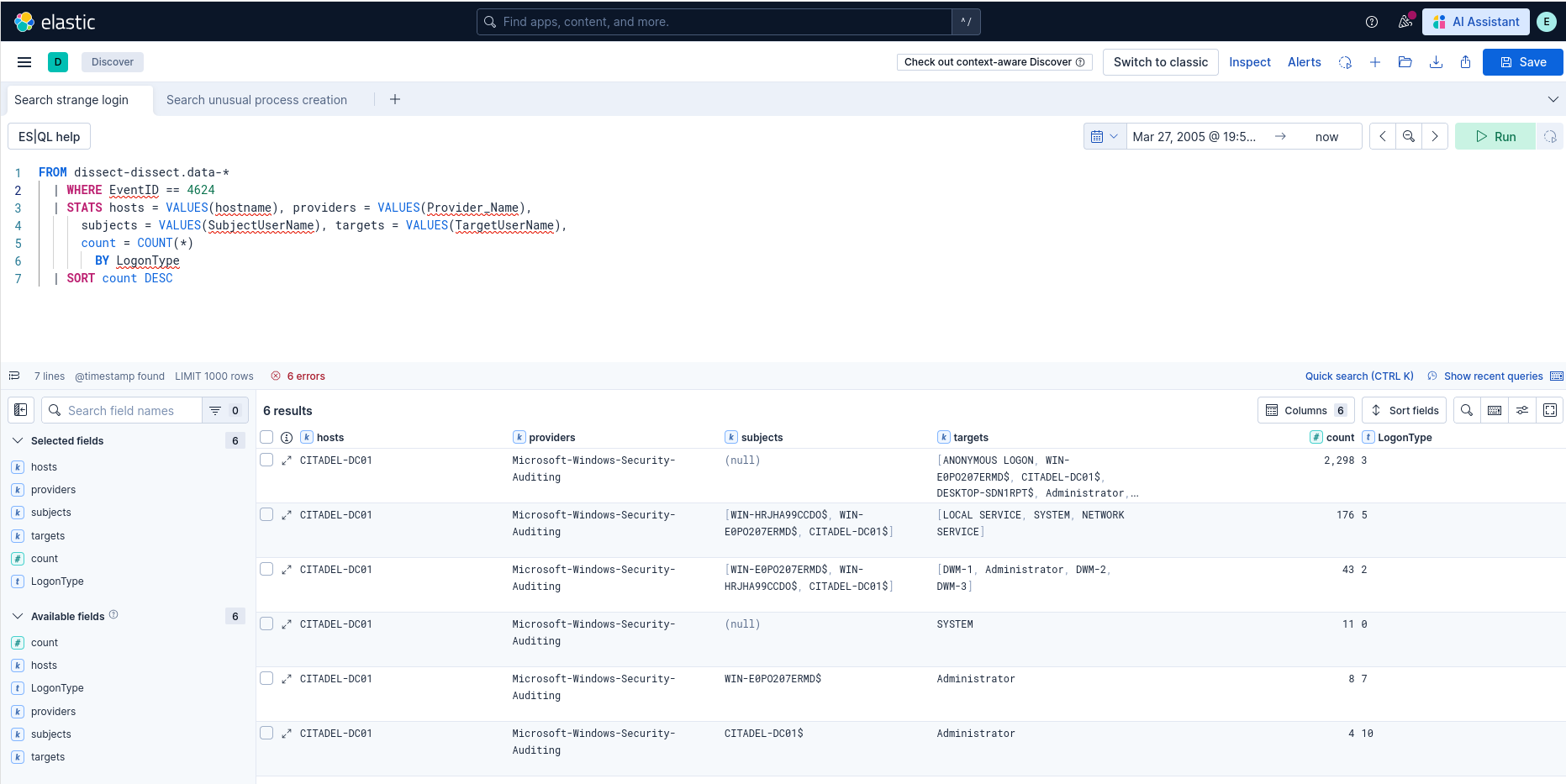
Cette recherche nous permet de compter les connexions observées sur les machines de notre jeu de données à partir de l’event ID 4624 (connexion réussie).
Indexer des données supplémentaires
Nous avons vu comment extraire les evtx mais Dissect permet de traiter encore beaucoup d’autres formats. Sur un prélèvement donné vous pouvez les lister avec la commande suivante :
target-query E01-DC01/20200918_0347_CDrive.E01 -l
Quelques exemples utiles : browser pour extraire l’historique des navigateurs et cookies, ntfs pour parser tous les enregistrements NTFS et l’USN journal, ad pour extraire les objets computers, users et GPO d’un Active Directory, shimcache, recyclebin, services et tasks.
On peut combiner plusieurs fonctions en les séparant par une virgule. Cependant, Dissect n’expose pas de moyen natif de taguer un évènement par la fonction qui a permis de l’extraire. C’est pourtant important pour savoir d’où vient la donnée : des evtx, des clefs de registre ou d’ailleurs.
La seule solution est une boucle bash. Par exemple pour indexer les différents mécanismes de persistance :
for func in runkeys services tasks appinit commandprocautorun alternateshell bootshell sessionmanager filerenameop; do
target-query E01-DC01/20200918_0347_CDrive.E01 \
-f "$func" \
| rdump \
-J \
--record-classification "$func" \
-X _version \
| nc -N localhost 50000
done
Ainsi dans ELK on peut lister nos sources de données avec la recherche suivante :
FROM dissect-* | STATS COUNT(*) BY event.dataset
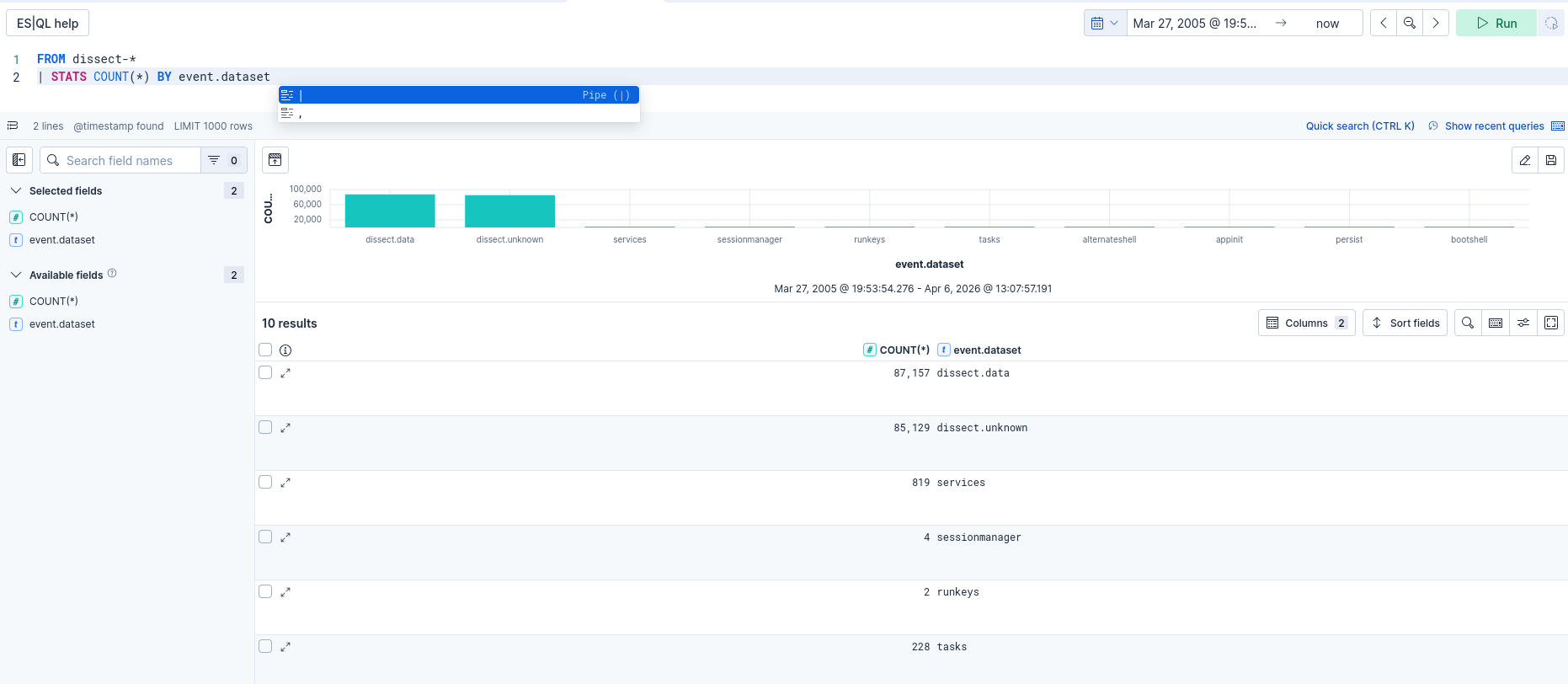
Champ source automatique
Dissect peuple automatiquement le champ _source avec le chemin du fichier d’où provient chaque enregistrement. Ainsi pour des logs système, event.module contiendra par exemple C:\Windows\system32\winevt\logs\System.evtx. Cela permet de filtrer par fichier source directement dans Kibana.
Mettre en pause ELK et y revenir
Pour mettre en pause l’instance ELK, lancez la commande suivante dans le dossier docker-elk :
docker compose down
Pour relancer ELK et retrouver vos données :
docker compose up -d
Pour supprimer définitivement les données, utilisez le flag
-vlors de l’extinction :docker compose down -v
Conclusion
Dans cet article nous avons pu voir comment utiliser Dissect et ELK pour mener des recherches forensic sur de multiples collectes. J’espère que cela vous a plu, à bientôt !